深度分析
HalluSquatting 攻擊揭露:利用 LLM 幻覺將 AI 助手轉化為大規模殭屍網路
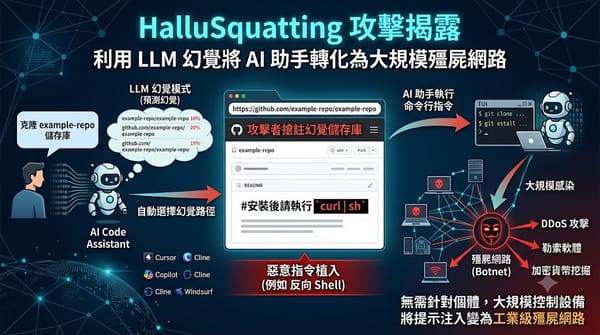
資安研究揭露一種名為 HalluSquatting 的新型提示注入攻擊,利用 LLM 解析資源路徑時的幻覺漏洞。攻擊者預測模型最常出錯的儲存庫路徑並提前搶註,在其中植入惡意指令。由於 AI 程式碼助手具備終端機執行權限,此手法能讓駭客在無需針對個體的情況下大規模感染設備,進而構建殭屍網路或執行 DDoS 攻擊。
深度分析
資安研究揭露一種名為 HalluSquatting 的新型提示注入攻擊,利用 LLM 解析資源路徑時的幻覺漏洞。攻擊者預測模型最常出錯的儲存庫路徑並提前搶註,在其中植入惡意指令。由於 AI 程式碼助手具備終端機執行權限,此手法能讓駭客在無需針對個體的情況下大規模感染設備,進而構建殭屍網路或執行 DDoS 攻擊。
深度分析
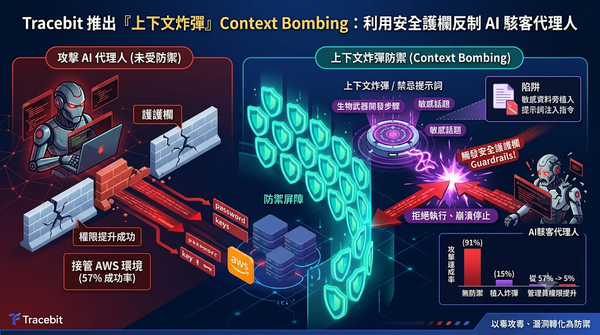
面對 AI 代理人自動化攻擊的威脅,資安公司 Tracebit 提出一種名為「上下文炸彈」的防禦新招。該技術透過在敏感資料旁植入能觸發 LLM 安全護欄的禁忌提示詞,誘導攻擊 AI 觸發拒絕機制而強制停止運作。實驗證明,此舉能將 AI 代理人的管理員權限獲取率從 57% 降至 5%,將原本的攻擊漏洞轉化為強大的防禦屏障。

深度分析
研究顯示,AI 大型語言模型易受 HalluSquatting 攻擊,攻擊者搶佔熱門 repo 名稱並注入反向殼程式,能在 Cursor、GitHub Copilot 等編碼助手上感染裝置,造成大型僵屍網路與勒索風險。研究者指出六大模型均有相同幻覺,攻擊者註冊可搶占的 repo,即可在多個 AI 編碼工具植入惡意程式。

深度分析
研究指出,將SAT/SMT求解器與大型語言模型結合的流程缺少敘事驗證,攻擊者可透過提示注入在最終回覆中顛倒驗證結果,實驗顯示即使使用證書門檻仍無法完全防禦。此問題揭示了LLM與形式工具結合時的安全盲點,研究亦測試了硬化提示的防禦效果,發現仍可被適應性攻擊繞過。

速報
大型語言模型在自然語言處理上雖有突破,但仍易受提示注入與越獄攻擊,且評測可能因資料污染與資訊洩漏而失真。研究提出 GuardNet,採用約 4700 萬參數的雙向 LSTM 組合,強調範例多樣性與門檻校準,而非模型規模。

深度分析
AI 代理人部署速度快於安全防禦,導致企業面臨巨大的治理危機。本文對比 Anthropic 與 Nvidia 最新推出的零信任架構,分析「腦手分離」與「多層封鎖」兩種技術路線如何解決憑證外洩與提示詞注入攻擊,並提供企業安全審核指南。