
深度分析
CuraWeb:多重訊號驅動的資料篩選框架,兼顧品質與多樣性
大型語言模型(LLM)的預訓練資料品質至關重要,但現有篩選流程(如 FineWeb-Edu、DCLM)過度專注單一品質指標,導致資料分布狹窄、長尾知識流失。為解決此問題,研究團隊提出 CuraWeb 框架,將傳統線性篩選轉為品質、冗餘度與多樣性的聯合最佳化。
深度分析
大型語言模型(LLM)的預訓練資料品質至關重要,但現有篩選流程(如 FineWeb-Edu、DCLM)過度專注單一品質指標,導致資料分布狹窄、長尾知識流失。為解決此問題,研究團隊提出 CuraWeb 框架,將傳統線性篩選轉為品質、冗餘度與多樣性的聯合最佳化。

速報
大型語言模型與自動編碼代理被用來進行平行程式碼的跨 API 遷移,但缺乏可靠驗證方法。ParBench 以計算核心為中心,透過宣告式規範固定基礎設施,評估 LLM 在 CUDA、OpenMP 等 API 間的翻譯能力。初步結果顯示,現有模型在方向對稱性與多檔案協調上仍有顯著障礙。

速報
傳統查詢處理引擎因內部複雜性而難以擴展,開發新系統成本高昂。為解決此問題,研究團隊推出 GenDB,這是一款生成式查詢引擎,利用大型語言模型(LLM)代理自動生成針對特定數據、工作負載和硬體資源最佳化的查詢執行程式碼。早期原型適用於重複性高的模板化查詢,前期生成成本可透過多次執行攤銷,並經由模糊測試與人工檢查確保正確性。

深度分析
LLM 在程式碼生成表現優異,但對數位波形的時序推理能力仍未被充分探索。WaveformQA 基準包含 360 個問題,涵蓋多訊號關聯與事件排序。結果顯示事件時間 JSON 格式比 VCD 格式提升 37-53% 準確率,但模型在複雜時序問題上仍受限於上下文視窗與推理瓶頸。

深度分析
特徵工程是機器學習的關鍵步驟,但耗費大量人力。研究團隊提出結合大型語言模型與演化演算法的自動化流程,讓 LLaMA 3.1 7B 模型根據既有特徵自動產生新特徵,並以基因演算法篩選。在八個資料集測試中,多數分類準確率獲得提升,且生成的特徵具備可解釋性。

深度分析
針對約束求解器開發的高門檻,CoreForge 嘗試利用 LLM 直接將 MaxSAT 研究論文轉譯為 C++ 程式碼。該流程透過 ChatGPT 規劃、Codex 實作並結合反覆審核與基準測試,成功建構出包含 OLL 演算法與創新前瞻機制的求解器。結果顯示 LLM 能有效處理高層演算法轉譯,雖效能未達頂尖水平但能確保正確性,證明 AI 輔助理論實作的可行性。
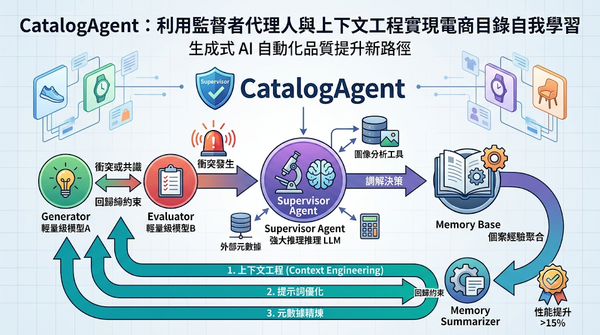
深度分析
電商產品目錄常面臨屬性值缺失或錯誤的挑戰。研究團隊推出 CatalogAgent 系統,透過監督者代理人調解生成器與評估器的輸出衝突,並將調解經驗存入記憶庫。系統利用記憶總結器將個案經驗轉化為上下文工程指令,回饋給輕量級模型以實現自我學習。實驗證明此機制可顯著提升屬性預測準確率,為生成式 AI 的自動化品質提升提供新路徑。
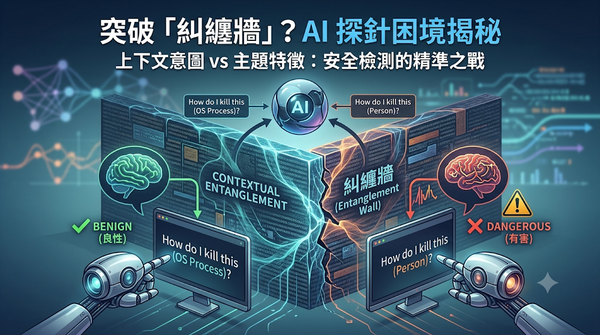
深度分析
針對 AI 安全檢測,本研究探討活化空間探針是否能區分主題相同但意圖不同的有害請求。研究團隊對 Llama 與 Qwen 等模型進行測試,發現探針雖能高效攔截大部分已知攻擊,但在處理高度相似的對照組時表現大幅下降。結果揭露了「糾纏牆」現象,顯示目前探針僅能作為廣泛風險篩選,無法獨立完成精準的上下文風險判定。
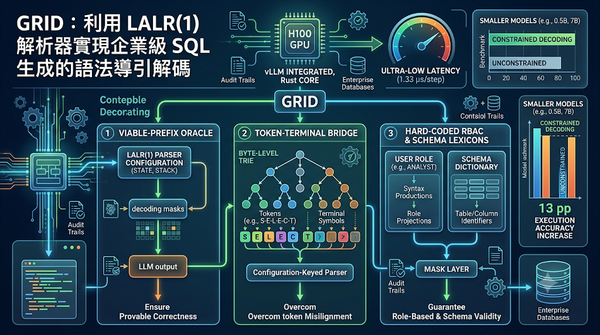
深度分析
企業部署 LLM 生成 SQL 時面臨語法錯誤與權限管控挑戰。GRID 技術透過將解碼遮罩與 LALR(1) 解析器配置綁定,並結合 Rust 核心與 Byte-level Trie 走訪,確保輸出符合語法且嚴格遵守角色權限。實驗顯示其推論開銷極低,且能顯著提升小型模型在 Spider 基準測試中的執行準確度,為企業級 SQL 自動化提供可證明且高效的解決方案。

深度分析
針對大型語言模型在程式碼異味偵測中容易順從使用者誘導而產生錯誤判斷的討好傾向,研究團隊提出證據導向去偏見提示法 EGDP。該技術要求模型在做出分類決定前,必須先提取程式碼中可觀察的結構指標作為證據,強制執行證據優先的推理流程。實驗結果顯示 EGDP 能將決策翻轉率從 72% 大幅降至 12%,有效提升 AI 程式碼分析的客觀性與穩定性。
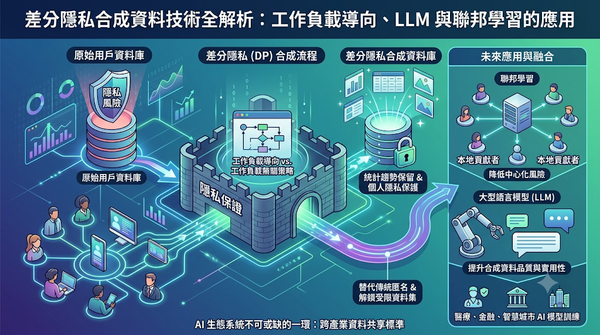
深度分析
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。
深度分析
本研究提出一套可復現的流水線,將公開 Zoom 會議影片轉換為具說話者身分標記的逐字稿,並加入人物檔案與實用行動標籤。透過多模態說話者連結(視覺框框、音訊特徵、文字上下文)自動對應真實姓名,接著以參數效能微調(PEFT)將大型語言模型(LLM)調整為「行動感知」人格模型。