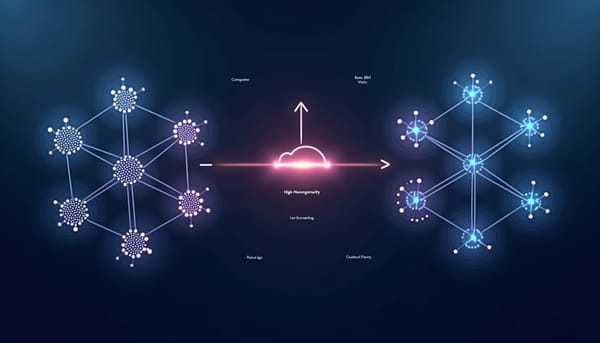
深度分析 LLM 特徵拼接在高同質性與低同質性圖神經網路上的表現差異分析 研究發現,將大型語言模型產生的節點特徵以純拼接方式加入圖神經網路,會在高同質性資料集如PubMed與Cora上大幅降低測試準確率,下降幅度最高達17個百分點;而在同質性較低的WikiCS與ogbn‑arxiv上則可提升數個百分點。作者提出以Δsig指標預測拼接效應,並建議使用可學門控或聯合訓練等機制避免負面影響。