深度分析
差分隱私合成資料技術全解析:工作負載導向、LLM 與聯邦學習的應用
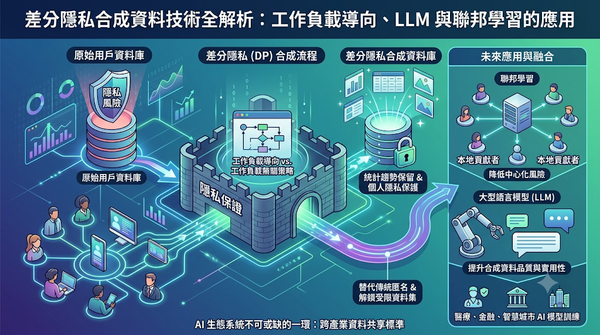
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。
深度分析
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。

深度分析
隨著網路攻擊手法持續演變,傳統 IDS 受限於資料稀缺與隱私限制。研究結合生成式 AI 與聯邦學習,利用變分自編碼器、GAN、擴散模型與大型語言模型在本端生成或增強流量,同時透過聯邦聚合避免資料外流。實驗顯示在多項基準上偵測率提升1%~3%,且通訊與運算成本下降15%~20%。

深度分析
本研究針對聯邦學習的演算法設計,提出Auto‑FL‑Research(AFR)框架,透過受限的程式碼代理在固定預算與通訊合約下搜尋訓練配方。實驗在五個醫療FLamby任務與六個LEAF設定上,以五次隨機種子重複驗證,四項任務顯著提升效能,亦揭示部分成果受種子敏感影響。

深度分析
在資料稀疏且客戶端參與不均的聯邦學習環境下,研究提出以熵正規化的機率門來維持稀疏模型的探索性,結合 L0 约束與硬混凝土分布,實驗顯示相較於 FedAvg 後剪枝或 Fed‑IHT,測試準確度與稀疏度恢復均有顯著提升。此外,方法在不同 GPU 架構與客戶端參與比例下仍保持穩定加速 15%~20% 的運算速度,預示未來在 AI 服務部署與成本優化上具備廣泛應用前景。
深度分析
聯邦學習因客戶端資料分布不一致而性能受損,研究提出FedXDS以XAI的特徵歸因指導資料共享,僅傳送屬於模型決策關鍵的特徵並加入度量差分隱私保護。實驗顯示在多客戶端與高異質性情境下,FedXDS能提升準確率與收斂速度,同時抵禦成員推論與特徵反演攻擊。此外,該方法僅需一次反向傳播即可取得歸因圖,減少計算開銷。

深度分析
跨組織文字協作易洩露組織指紋,研究提出 DiSan 以角色與風格分離的雙流編碼,削減 PII 曝露 20 倍,同時保留 83% 回答忠實度。此框架透過聯邦原型對齊與對抗正則化,避免集中原始文本,並在 Enron 電子郵件測試中降低 73% 風格辨識率。研究顯示,僅遮蔽 19% 標記詞無法顯著降低風格屬性,證明傳統遮蔽不足。

深度分析
聯邦學習允許多端共同訓練模型,卻可能被惡意客戶端利用硬體位翻注入後門。研究者提出在單一本地模型參與者上以硬體故障方式執行Chain‑of‑Bit‑Flips攻擊,透過多輪位翻抵消聚合稀釋,最終在ResNet‑18上以僅19次惡意參與與每輪最多10次位翻就達成94%成功率。

速報
隨著雲端、物聯網與邊緣運算的普及,分散式基礎建設的資安攻擊面持續擴大,傳統集中式入侵偵測面臨可擴展性、隱私保護與運算透明度等挑戰。研究提出結合聯邦學習、可解釋人工智慧與認知資安分析的框架,讓各節點在本地訓練安全模型,僅以加密的模型參數進行聯邦聚合,降低資料傳輸需求並提升隱私。

深度分析
隨著智慧企業需要在保護隱私的同時進行分散式學習,研究提出TITAN‑FedAnil+結合區塊鏈與適應性聚合,以過濾惡意更新並減少記憶體負擔。實驗顯示在8 GB邊緣設備上,記憶體使用降低至81%,且在20輪訓練中保持超過92%的準確度。同時提供區塊鏈共識的狀態簽名機制,確保模型不可篡改。

速報
分散式事件系統在即時資料傳輸、物聯網與雲端微服務中扮演關鍵角色,但其鬆耦合與非同步傳遞也擴大了攻擊面。研究提出 SECUREVENT,結合驗證傳輸、主題授權、簽名事件等傳統防護與線上異常偵測、圖形行為特徵、複雜事件規則、聯邦學習與對抗式機器學習治理的混合式安全監控架構。

深度分析
聯邦學習在分散式訓練中保護資料隱私,但面臨惡意客戶端(拜占庭)更新破壞全域模型收斂的風險。該研究把客戶端挑選重構為一個 QUBO(二元二次無約束優化)問題,將成對距離編入成本函數,以量子退火器搜尋整體最佳子集,取代 MultiKrum 的逐一貪婪評分。