
速報
PolyWorkBench:多語言長程工作流程的 LLM 代理人基準測試
研究針對大型語言模型(LLM)代理人在多語言長程工作流程中的表現,推出全新基準 PolyWorkBench,涵蓋商務、知識工作、法律、在地化與製造五大領域,共 67 項任務。測試要求代理人處理多語言輸入、迭代推理、呼叫外部工具並產出結構化結果,並以結構評分、可執行驗證與語意評估三層框架進行評估。
速報
研究針對大型語言模型(LLM)代理人在多語言長程工作流程中的表現,推出全新基準 PolyWorkBench,涵蓋商務、知識工作、法律、在地化與製造五大領域,共 67 項任務。測試要求代理人處理多語言輸入、迭代推理、呼叫外部工具並產出結構化結果,並以結構評分、可執行驗證與語意評估三層框架進行評估。

速報
研究指出,神經網路的非線性不必只能靠傳統激活函式,透過輸入條件化的門檻閘門 (Threshold Gating, TG) 也能達成同樣效果。

速報
OpenClaw 服務在長前置工作負載下需提升效能。研究在單節點環境調整 chunked‑prefill、張量平行與管線平行參數,最佳配置為 3072/TP4/PP4/最大 24 同時請求。此設定將請求吞吐提升至 0.48 req/s,平均回應時間降至 6.69 秒,估計服務成本下降約 10%。

速報
大型語言模型(LLM)常會產出流暢但錯誤的回應,缺乏即時驗證機制。研究者提出 Heaviside Continuity of Rolling Coefficients(HCRC),將推理重新定義為受 Heaviside Gate 控制的謂詞門檻狀態轉換。

速報
隨著人工智慧模型功能日益強大,確保其輸出符合使用者意圖變得關鍵。傳統的辯論式驗證依賴兩個能力相當且其中一方誠實的模型,現實中難以保證。研究者提出單證明互動驗證概念,針對具備人類判斷或網路查詢等外部資訊的運算,設計雙重高效的單證明互動證明與論證。

速報
研究結合了具備可執行動作與持續狀態的基礎測試與語言代理人互動的社會模擬,提出 Incognita 框架,將社會互動與具體執行分離。框架內部將訊息路由至使用者或專家,專家審核後交由確定性子環境執行,最後由離線評估器給予獎勵。
速報
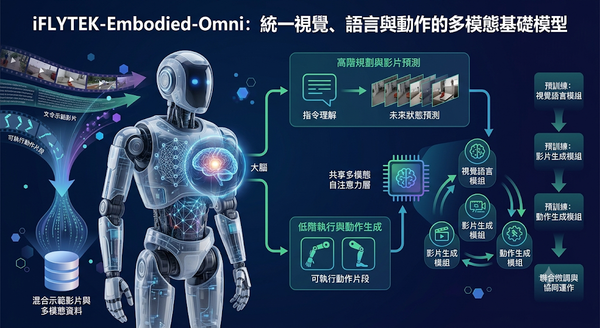
為提升通用型具身代理人的指令理解與長期控制能力,研究團隊打造 iFLYTEK-Embodied-Omni,採用視覺語言、影片生成與動作生成的共享多模態自注意力架構。模型將高階規劃與低階執行分工協作,並以混合示範影片進行四階段訓練,顯著提升任務執行的準確度與穩定性。

速報
Hephaestus 在 GitHub Trending 上快速上升,因其模型無關的代理人作業系統能將專精代理人集中於 hub,並即時以暫時編排器處理任務。支援多種大型語言模型,具備本機優先設計,讓開發者免除重複建置。此熱度顯示社群對多代理人協作框架的需求。

速報
研究團隊推出 PreScience 資料集,彙整近十萬篇最新 AI 研究論文及其作者、引用與主題標籤,形成 502,000 筆完整記錄。資料集支援七項預測任務,包括貢獻生成、合作夥伴預測、先前工作挑選、引用次數與未來結合預測,以及主題趨勢預測。

速報
近期工具與記憶中毒攻擊揭示,外部工具與持續記憶會成為代理系統的新攻擊面。研究者提出 ElephantAgent,透過在每次查詢前重新計算並驗證局部上下文狀態的摘要,利用受信硬體維持線性化的授權狀態變更帳本,偵測並阻止未授權的狀態篡改。

速報
研究顯示,人工智慧代理人在相同資料與問題下,透過切換不同人物角色,可產生與人類研究團隊相似的意識形態差異,甚至重現 72% 的意識形態落差。超過八成的 AI 報告通過獨立 AI 審核,七成以上通過人類專家多數審核,說明問題不在分析本身,而是選擇與報告的偏好。

速報
強化學習驗證回饋常只用於單回合更新,缺乏跨回合資訊。研究者提出程序記憶蒸餾(PMD),將跨回合的驗證訊號整理為可重用的程序記憶,並在訓練中蒸餾至模型權重。實驗顯示 PMD 在兩大基準上分別提升 3.8‑5.5% 與 7.9‑13.6%,凍結任一環節會使效能下降逾 10%。